



Postgres: Extend schema with SQL functions¶
Table of contents
What are custom SQL functions?¶
Custom SQL functions are user-defined SQL functions that can be used to either encapsulate some custom business logic or extend the built-in SQL functions and operators. SQL functions are also referred to as stored procedures.
Hasura GraphQL engine lets you expose certain types of custom functions as top level fields in the GraphQL API to allow
querying them with either queries or subscriptions, or for VOLATILE functions as mutations.
Note
Custom SQL functions can also be queried as computed fields of tables.
Supported SQL functions¶
Currently, only functions which satisfy the following constraints can be exposed as top level fields in the GraphQL API (terminology from Postgres docs):
- Function behaviour:
STABLEorIMMUTABLEfunctions may only be exposed as queries.VOLATILEfunctions may be exposed as mutations or queries. - Return type: MUST be
SETOF <table-name>OR<table-name>where<table-name>is already tracked - Argument modes: ONLY
IN
Creating SQL functions¶
SQL functions can be created using SQL statements which can be executed as follows:
- Head to the
Data -> SQLsection of the Hasura console - Enter your create function SQL statement
- Hit the
Runbutton
Create a migration manually and add your create function SQL statement to the
up.sqlfile. Also, add an SQL statement that reverts the previous statement to thedown.sqlfile in case you need to roll back the migrations.Apply the migration by running:
hasura migrate apply
You can add a function by making an API call to the run_sql metadata API:
POST /v1/query HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "run_sql",
"args": {
"sql": "<create function statement>"
}
}
Track SQL functions¶
Functions can be present in the underlying Postgres database without being exposed over the GraphQL API. In order to expose a function over the GraphQL API, it needs to be tracked.
While creating functions from the Data -> SQL page, selecting the Track this checkbox
will expose the new function over the GraphQL API right after creation if it is supported.
You can track any existing supported functions in your database from the Data -> Schema page:
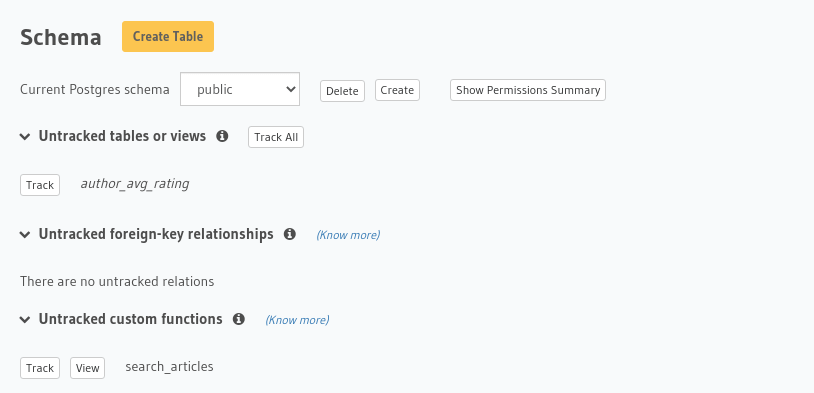
To track the function and expose it over the GraphQL API, edit the
functions.yamlfile in themetadatadirectory as follows:- function: schema: public name: <function name>
Apply the metadata by running:
hasura metadata apply
To track the function and expose it over the GraphQL API, make the following API call to the track_function metadata API:
POST /v1/query HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "track_function",
"args": {
"schema": "public",
"name": "<name of function>"
}
}
Note
If the SETOF table doesn’t already exist or your function needs to return a custom type i.e. row set,
create and track an empty table with the required schema to support the function before executing the above
steps.
Use cases¶
Custom functions are ideal solutions for retrieving some derived data based on some custom business logic that requires user input to be calculated. If your custom logic does not require any user input, you can use views instead.
Let’s see a few example use cases for custom functions:
Example: Text-search functions¶
Let’s take a look at an example where the SETOF table is already part of the existing schema:
articles(id integer, title text, content text)
Let’s say we’ve created and tracked a custom function, search_articles, with the following definition:
CREATE FUNCTION search_articles(search text)
RETURNS SETOF articles AS $$
SELECT *
FROM articles
WHERE
title ilike ('%' || search || '%')
OR content ilike ('%' || search || '%')
$$ LANGUAGE sql STABLE;
This function filters rows from the articles table based on the input text argument, search i.e. it
returns SETOF articles. Assuming the articles table is being tracked, you can use the custom function
as follows:
query {
search_articles(
args: {search: "hasura"}
){
id
title
content
}
}
Example: Fuzzy match search functions¶
Let’s look at an example of a street address text search with support for misspelled queries.
First install the pg_trgm PostgreSQL extension:
CREATE EXTENSION pg_trgm;
Next create a GIN (or GIST) index in your database for the columns you’ll be querying:
CREATE INDEX address_gin_idx ON properties
USING GIN ((unit || ' ' || num || ' ' || street || ' ' || city || ' ' || region || ' ' || postcode) gin_trgm_ops);
And finally create the custom SQL function in the Hasura console:
CREATE FUNCTION search_properties(search text)
RETURNS SETOF properties AS $$
SELECT *
FROM properties
WHERE
search <% (unit || ' ' || num || ' ' || street || ' ' || city || ' ' || region || ' ' || postcode)
ORDER BY
similarity(search, (unit || ' ' || num || ' ' || street || ' ' || city || ' ' || region || ' ' || postcode)) DESC
LIMIT 5;
$$ LANGUAGE sql STABLE;
Assuming the properties table is being tracked, you can use the custom function as follows:
query {
search_properties(
args: {search: "Unit 2, 25 Foobar St, Sydney NSW 2000"}
){
id
unit
num
street
city
region
postcode
}
}
Example: PostGIS functions¶
Let’s take a look at an example where the SETOF table is not part of the existing schema.
Say you have 2 tables, for user and landmark location data, with the following definitions (this example uses the popular spatial database extension, PostGIS):
-- User location data
CREATE TABLE user_location (
user_id INTEGER PRIMARY KEY,
location GEOGRAPHY(Point)
);
-- Landmark location data
CREATE TABLE landmark (
id SERIAL PRIMARY KEY,
name TEXT,
type TEXT,
location GEOGRAPHY(Point)
);
In this example, we want to fetch a list of landmarks that are near a given user, along with the user’s details in
the same query. PostGIS’ built-in function ST_Distance can be used to implement this use case.
Since our use case requires an output that isn’t a “subset” of any of the existing tables i.e. the SETOF table
doesn’t exist, let’s first create this table and then create our location search function.
create and track the following table:
-- SETOF table CREATE TABLE user_landmarks ( user_id INTEGER, location GEOGRAPHY(Point), nearby_landmarks JSON );
create and track the following function:
-- function returns a list of landmarks near a user based on the -- input arguments distance_kms and userid CREATE FUNCTION search_landmarks_near_user(userid integer, distance_kms integer) RETURNS SETOF user_landmarks AS $$ SELECT A.user_id, A.location, (SELECT json_agg(row_to_json(B)) FROM landmark B WHERE ( ST_Distance( ST_Transform(B.location::Geometry, 3857), ST_Transform(A.location::Geometry, 3857) ) /1000) < distance_kms ) AS nearby_landmarks FROM user_location A where A.user_id = userid $$ LANGUAGE sql STABLE;
This function fetches user information (for the given input userid) and a list of landmarks which are
less than distance_kms kilometers away from the user’s location as a JSON field. We can now refer to this
function in our GraphQL API as follows:
query {
search_landmarks_near_user(
args: {userid: 3, distance_kms: 20}
){
user_id
location
nearby_landmarks
}
}
Querying custom functions using GraphQL queries¶
Aggregations on custom functions¶
You can query aggregations on a function result using the <function-name>_aggregate field.
For example, count the number of articles returned by the function defined in the text-search example above:
query {
search_articles_aggregate(
args: {search: "hasura"}
){
aggregate {
count
}
}
}
Using arguments with custom functions¶
As with tables, arguments like where, limit, order_by, offset, etc. are also available for use with
function-based queries.
For example, limit the number of articles returned by the function defined in the text-search example above:
query {
search_articles(
args: {search: "hasura"},
limit: 5
){
id
title
content
}
}
Using argument default values for custom functions¶
If you omit an argument in the args input field then the GraphQL engine executes the SQL function without the argument.
Hence, the function will use the default value of that argument set in its definition.
For example: In the above PostGIS functions example, the function definition can be updated as follows:
-- input arguments distance_kms (default: 2) and userid
CREATE FUNCTION search_landmarks_near_user(userid integer, distance_kms integer default 2)
Search nearby landmarks with distance_kms default value which is 2 kms:
query {
search_landmarks_near_user(
args: {userid: 3}
){
user_id
location
nearby_landmarks
}
}
Accessing Hasura session variables in custom functions¶
Create a function with an argument for session variables and track it with the track_function_v2 API with the
session_argument config set. The session argument will be a JSON object where keys are session variable names (in lower case)
and values are strings. Use the ->> JSON operator to fetch the value of a session variable as shown in the
following example.
-- single text column table
CREATE TABLE text_result(
result text
);
-- simple function which returns the hasura role
-- where 'hasura_session' will be session argument
CREATE FUNCTION get_session_role(hasura_session json)
RETURNS SETOF text_result AS $$
SELECT q.* FROM (VALUES (hasura_session ->> 'x-hasura-role')) q
$$ LANGUAGE sql STABLE;
query {
get_session_role {
result
}
}
Note
The specified session argument will not be included in the <function-name>_args input object in the GraphQL schema.
Tracking functions with side effects¶
You can also use the track_function_v2 API to track VOLATILE functions as mutations.
Aside from showing up under the mutation root (and presumably having
side-effects), these tracked functions behave the same as described above for
queries.
We also permit tracking VOLATILE functions under the query root, in
which case the user needs to guarantee that the field is idempotent and
side-effect free, in the context of the resulting GraphQL API. One such use
case might be a function that wraps a simple query and performs some logging
visible only to administrators.
Note
It’s easy to accidentally give an SQL function the wrong volatility (or for a
function to end up with VOLATILE mistakenly, since it’s the default).
Permissions for custom functions¶
A custom function f is only accessible to a role r if there is a function permission (see Create function permission) defined on the function f for the role r. Additionally, role r must have SELECT permissions on the returning table of the function f.
Access control permissions configured for the SETOF table of a function are also applicable to the function itself.
For example, in our text-search example above, if the role user has access only to certain columns of
the table article, a validation error will be thrown if the search_articles query is run selecting a column
to which the user role doesn’t have access to.
Note
In case of functions exposed as queries, if the Hasura GraphQL engine is started with inferring of function permissions
set to true (by default: true) then a function exposed as a query will be accessible to a role even
if the role doesn’t have a function permission for the function - provided the role has select permission defined
on the returning table of the function.
 Thank you for subscribing to our newsletter!
Thank you for subscribing to our newsletter!